Bioinformatics Concepts
Background
CosmosID provides a platform to upload, process, and manage your metagenomic samples. To help you understand how our bioinformatics analysis works we will define a few terms. kmer - a kmer is a nucleotide sequence of a certain length. It is common in genomics to select all possible kmers of a fixed length for each read in a sample, for example. wgs - whole genome shotgun sequencing - with this method of DNA sequencing, all microbial DNA in the sample is fragmented into small pieces for next-generation sequencing. shotgun metagenomics - using wgs sequencing as described above, the CosmosID algorithms identify microorganisms based on the entire genomes of the organisms that are in our database. amplicon/16S/ITS - unlike shotgun metagenomics, amplicon (or 16S/ITS) analysis looks only at the relevant conserved ribosomal RNA gene or genes, not the entire genome for identification.More details on CosmosID
CosmosID uses a kmer based approach to identify microorganisms in metagenomic samples. Specifically, for metagenomics, CosmosID identifies unique and shared kmers in reference genomes and stores them in our reference database. When a sample is submitted for analysis, we search the kmers in the sample against the kmers in our database to find matches that help us identify the microbes present in the sample.CosmosID Curated Databases
The CosmosID databases are organized phylogenetically and contain hundreds of millions of marker gene sequences. The markers represent both coding and non-coding sequences uniquely identified by taxon and/or distinct nodes of phylogenetic trees. This means that the tree structure was created based on genomic relatedness of organisms rather than predetermined taxonomy based on phenotype. This allows CosmosID to have a high degree of accuracy in identifying microorganisms based on their DNA in metagenomic samples. It also helps identify the closest match to genomes that do not have strain level references in the database (if, for example, they have never been sequenced before). Another advantage of using the CosmosID databases is that they have been cleaned to remove contaminating sequences that are commonly found in DNA repositories. Additionally, we frequently update our databases to include new genomes that have been added to the sequencing space.Types of Databases
Organism databases:- Bacteria
- Viruses
- Fungi
- Protists
- Respiratory Viruses
- Antibiotic Resistance
- Virulence Factor
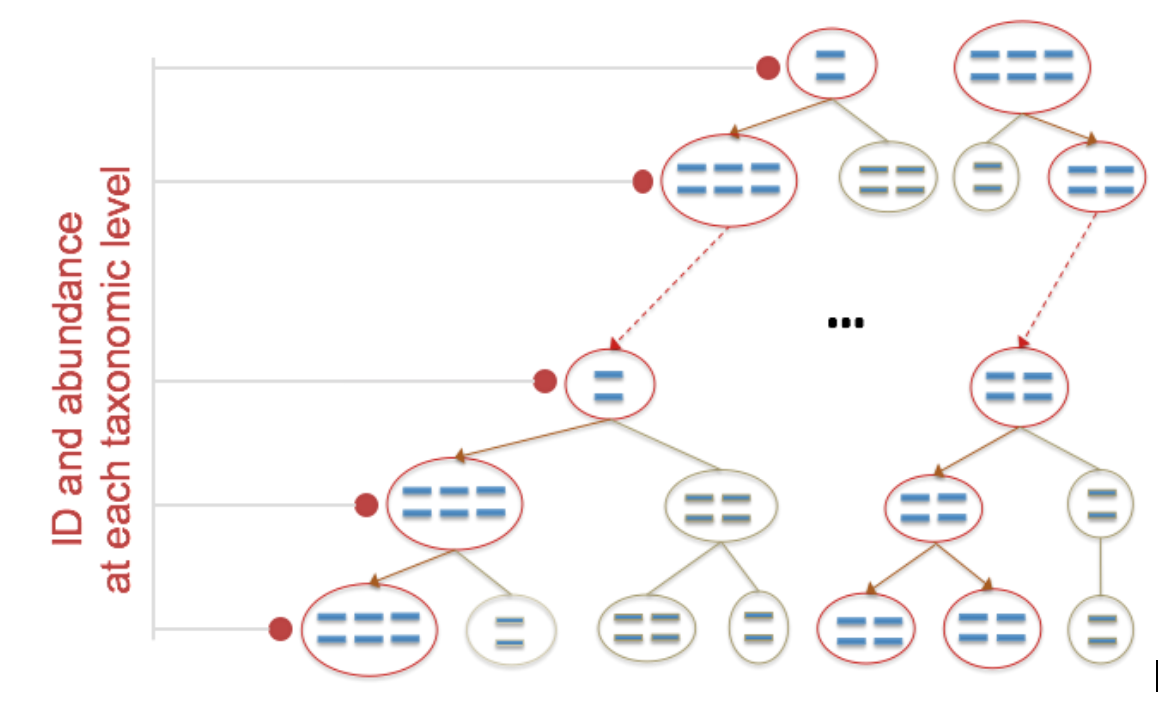
Identification at Different Taxonomic Levels
Figure 1: ID and abundance at each taxonomic level